
➡️Image Datasets
Providing Image-based datasets
Image labelling is the process of assigning labels to an image or set of images. Labels can be as simple as classifying an object as a “cat” or “bicycle”, or as complex as recognizing an action in a sequence of images.
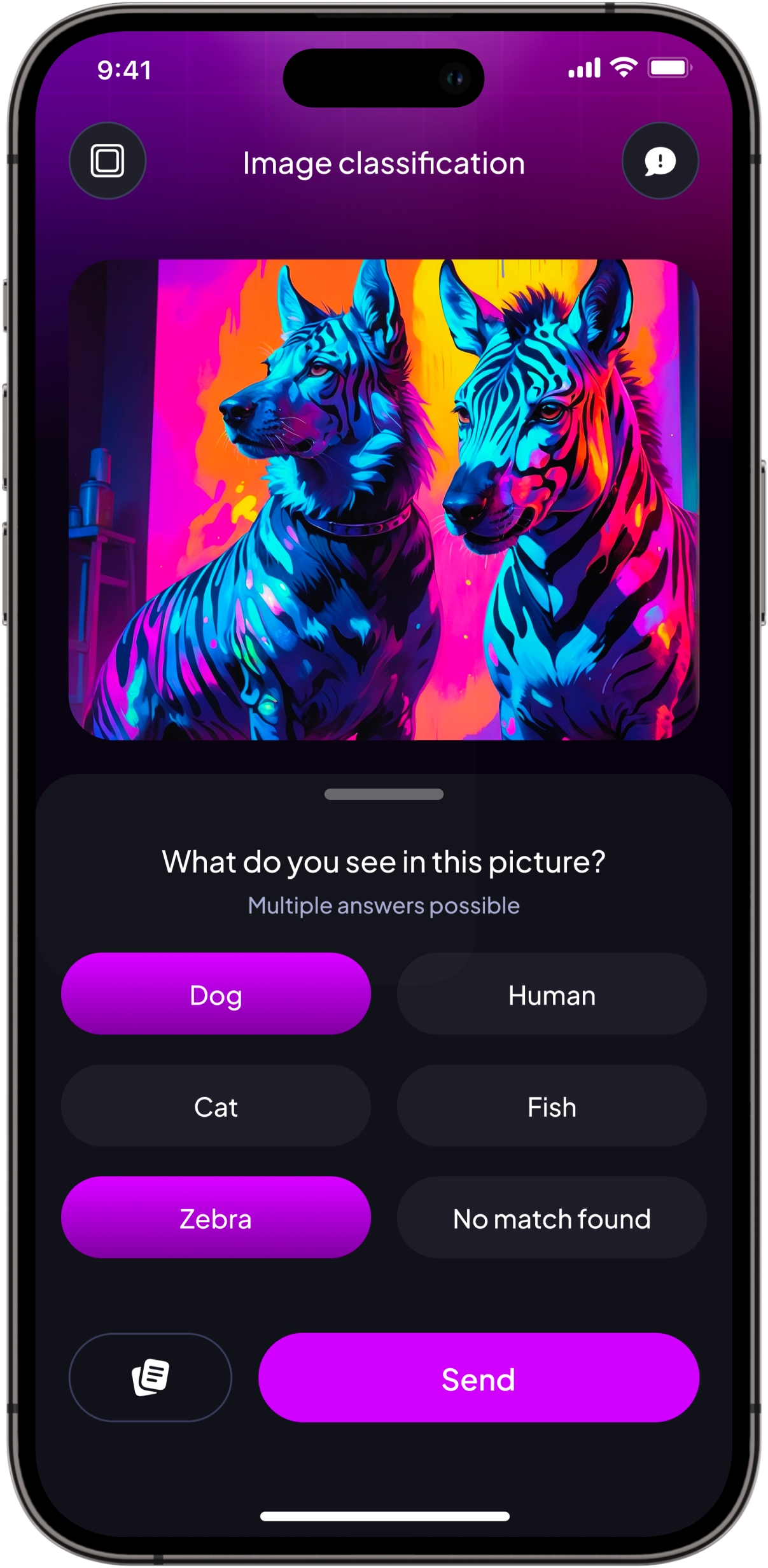
Image labeling is a crucial component of many computer vision applications, including object detection, scene understanding, and image classification. Here are some examples you might know:
Tesla's auto-pilot uses these datasets to train on recognizing roads, pedestrians, signs, and more.
Facial recognition systems on smartphones, used to unlock them, are also trained on these types of datasets.
In the field of computer vision, there are seven methods of labeling. Here are brief descriptions of some of them:
Classification: The process of assigning a label or class to an image, such as a person, object, scene, or activity. This is already implemented in Ta-da.
Polygons: A type of image annotation used to label the boundaries of objects in an image. It involves manually drawing polygons around objects of interest in an image, such as cars, buildings, people, etc. This type of annotation is commonly used to train deep learning algorithms for object detection and segmentation.
Semantic segmentation: Used to assign a semantic label to each pixel in an image, such as "cat" or "road." These labels can then be used to classify the image into different objects and scenes. This technology is useful in a variety of applications, such as autonomous driving, medical imaging, and satellite image analysis.
Bounding box: A rectangular box that is drawn around an object in an image. It defines the area of the object and is used to label the object by specifying the coordinates of the box. For example, a bounding box for an image of a cat might be drawn around the cat. Technically speaking, we store the coordinates of the box’s top left corner, the width and height of the box, and the class of the object (e.g., cat). Below is an example of a bounding box drawn around a cat:
